该博客充当笔记本
一、网络基础构成
以最基础的CNN网络架构为例:包含卷积层、池化层和全连接层
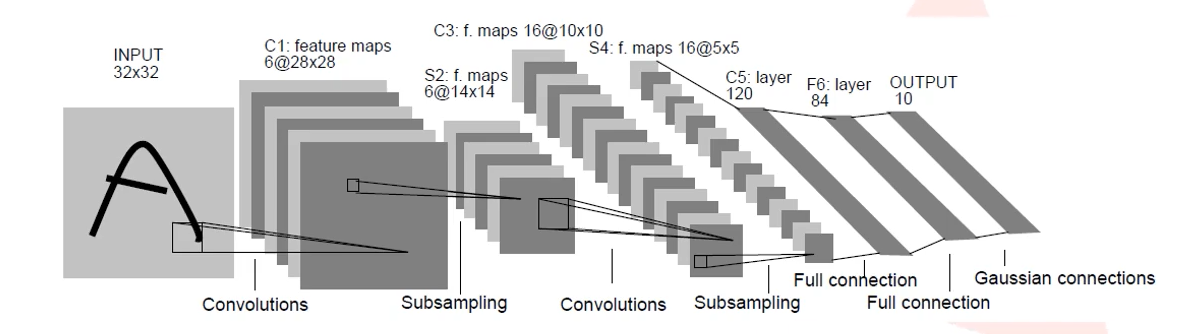
作用
卷积层:用N个卷积核提取N维特征,并且缩小图片的大小,使得展平后运算量不大
池化层(下采样层):用于降维减少神经网络的参数数量、扩大感受野、实现不变性
全连接层:起分类器的作用,且一定程度保留模型复杂度
1.卷积层
卷积特性:具有局部感知机制、权值共享
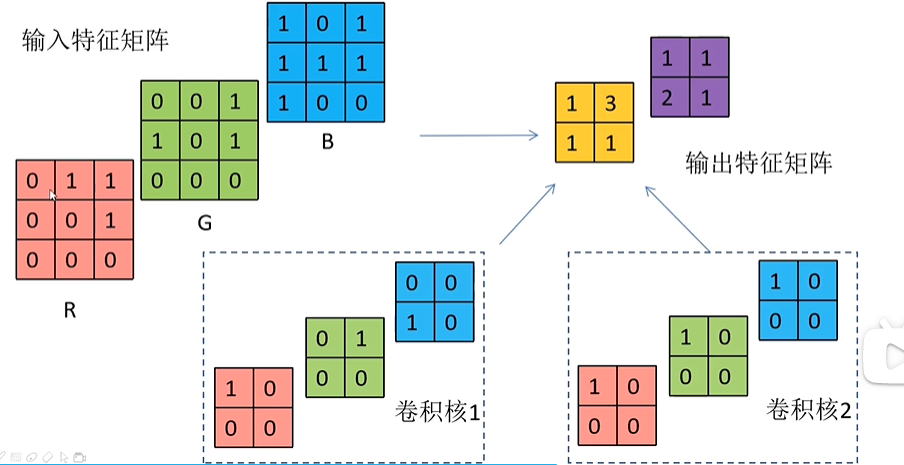
⚠输入特征矩阵深度=卷积核深度
⚠输出特征矩阵个数(map个数)=卷积核个数 (即可以提取各种各样的特征map)

W:输入图片大小
F:卷积核(filter)大小
P:边缘扩充(padding)大小,一般左右和上下同时扩充,所以是2P
S:步长Stride
一层卷积的参数计算:HxWx输入特征层的深度x卷积核个数,如上图为3x3x3x2
2.池化层
最大池化和平均池化
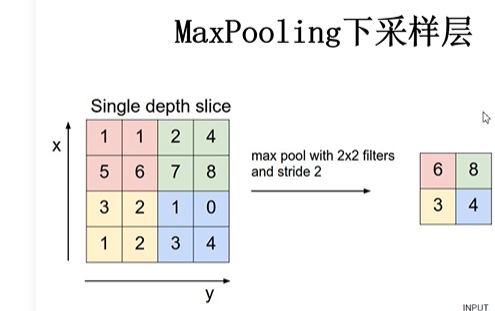
作用:对特征图进行稀疏处理,减少数据运算量。有待补充
3.全连接层
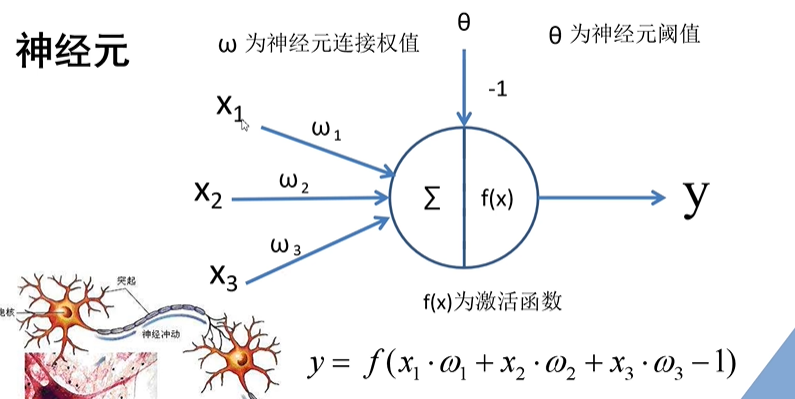
参数数量:一个神经元就有一套参数,池化和卷积就是为了减少参数数量和提取特征而出现的
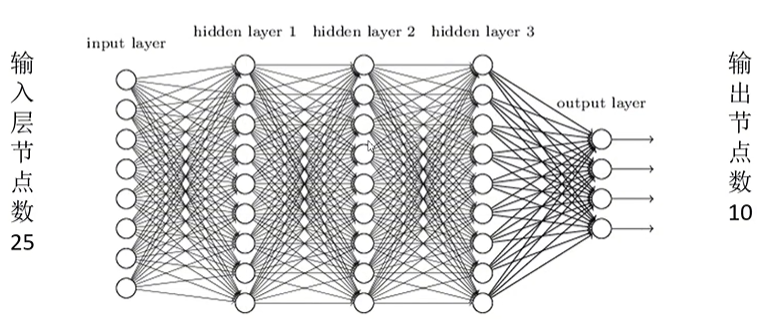
对全连接层FC的理解
作用一:把分布式特征representation映射到样本标记空间。人话:把卷积池化展平后的一堆数字进行全连接层里面的运算从而达到分类,就是分类。
作用二:用多层隐含层去拟合数据分布(非线性)。网上一种说法是类比于泰勒公式,每一层隐含层是神经元和激活函数组成,用多层非线性的函数(泰勒公式里的子项)来拟合更贴近于生活的非线性数据分布。这可能就是为什么需要用这种权重和偏置值的公式的原因。
对激活函数的理解
增加模型的非线性特性
有待补充
二、反向传播算法BP
1.误差的计算(Loss值,也称误差梯度值)
全连接神经网络如下所示,有一个隐含层,正向传播的出Loss需要经过三步:
- 多层公式计算得出输出层y神经元的值,是归一化得到各标签实际概率
- 将标签实际概率和标签理论概率用目标函数得出Loss
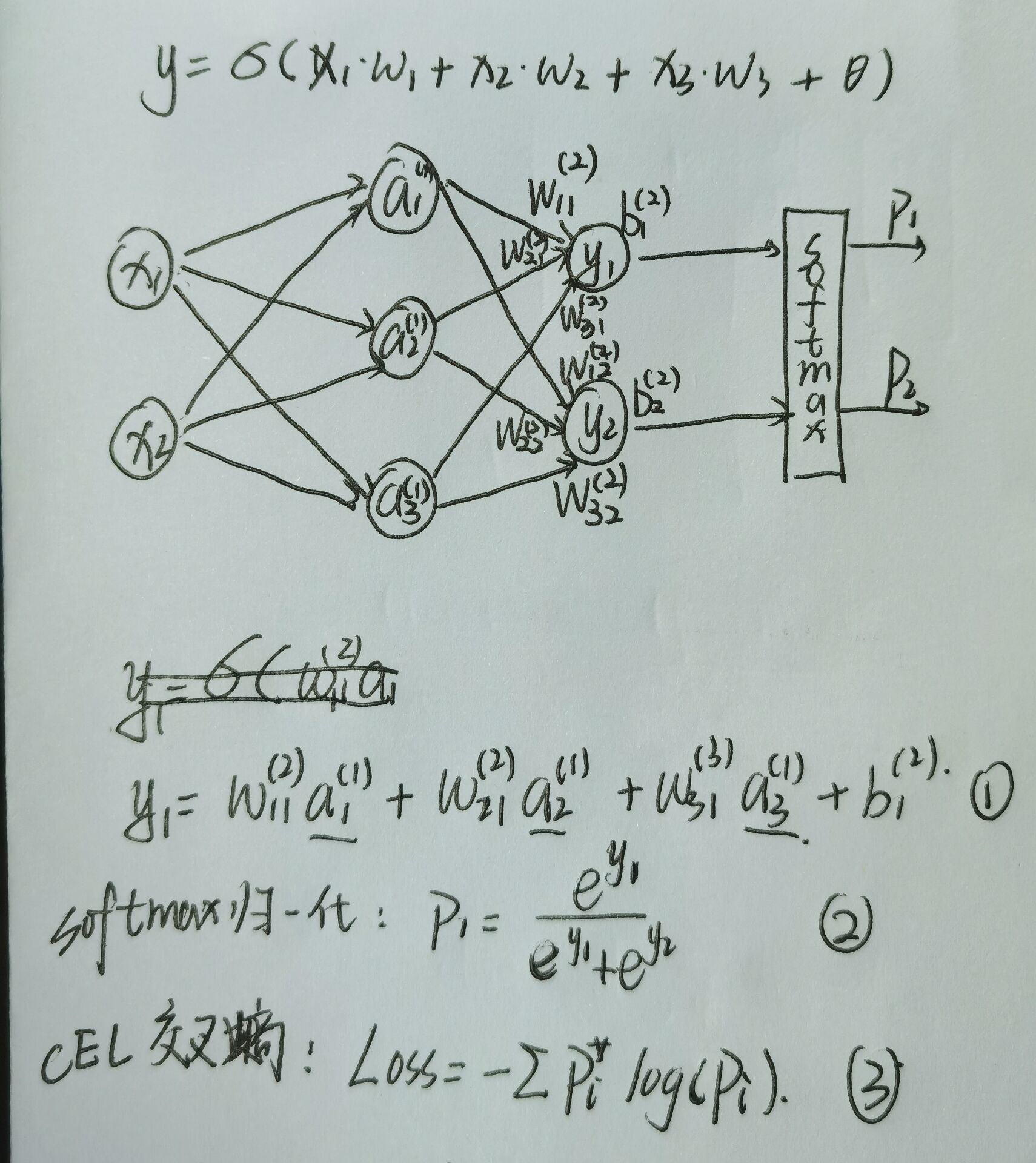
2.误差的反向传播(采用误差梯度)
误差的反向传播使用的是梯度下降法,误差梯度的本质是一个向量,而不是一个具体的标量值。计算方法如下图所示,采用了链式法则。

⚠⚠⚠⚠这里的梯度g(w)不是loss值,上图写错了。loss误差是标量,是根据目标函数算出来的一个衡量神经网络计算结果与理想结果差距的值,上述用了交叉熵目标函数;而误差梯度是误差对某一个权重参数w的偏导,是矢量。
3.权重的更新(梯度下降法、优化器)
【官方双语】深度学习之梯度下降法 Part 2 ver 0.9 beta_哔哩哔哩_bilibili
梯度下降法(SGD)原理解析及其改进优化算法 (内包含对batch的理解)
将误差梯度放入优化器中进行权重的调整,一步一步将损失梯度调整到最小,此时权重最适合目标网络。
目前普遍的优化器有SGD、Adam等,其中SGD的函数表示:

这里的权重w是一个向量,是一整个层的参数矩阵的某一列向量
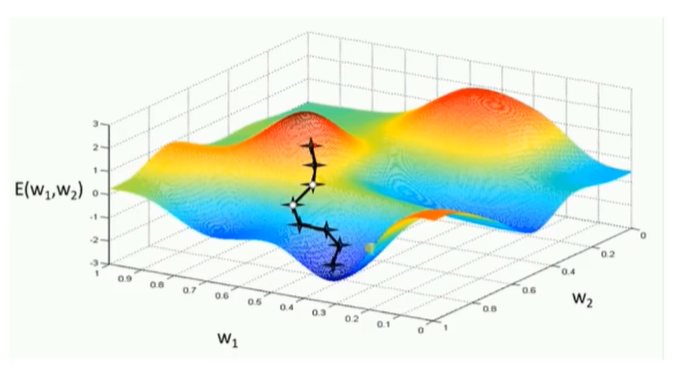
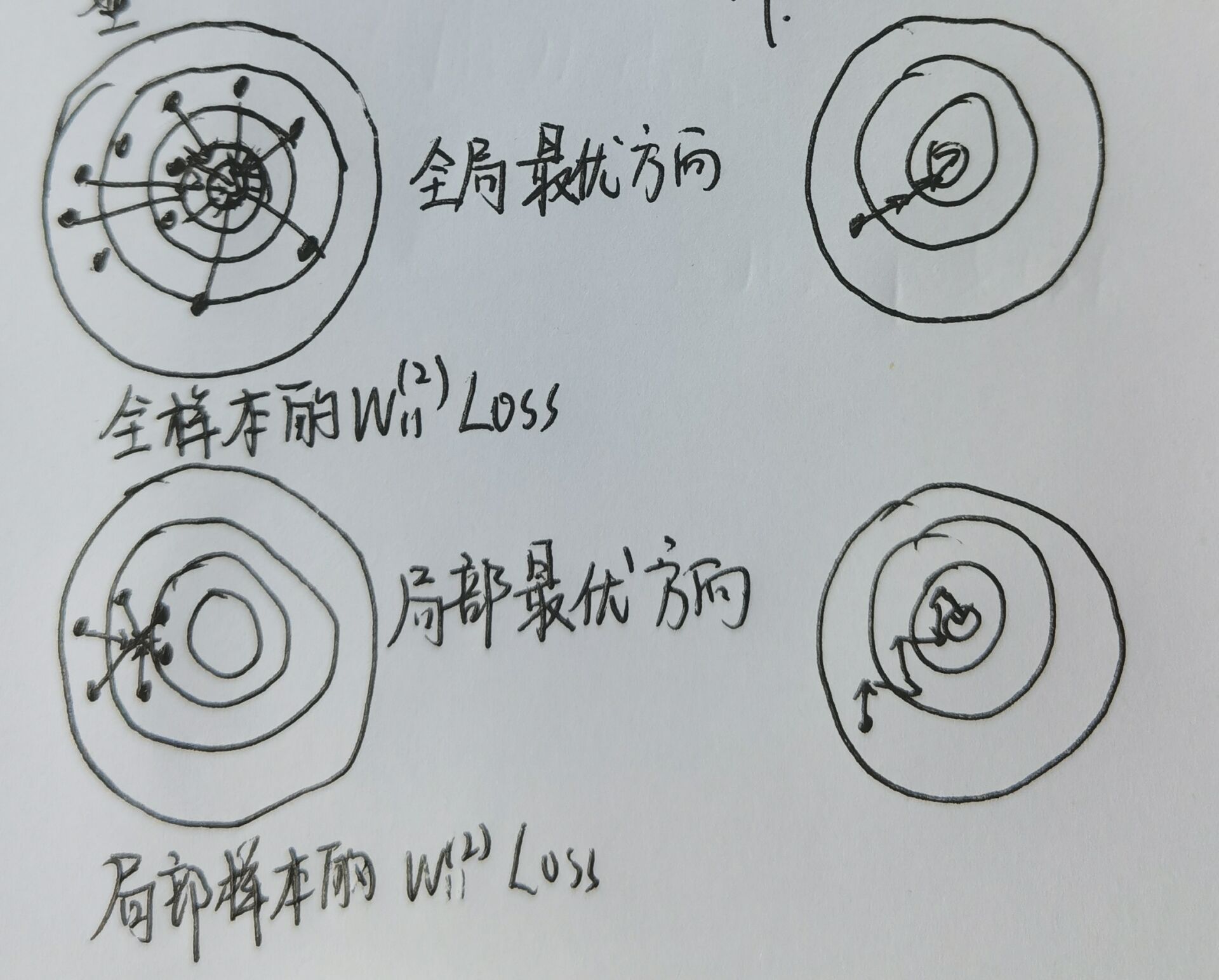
批训练导致梯度下降到局部最优的理解
如下图为一个权重的梯度空间,如果导入全部图片的训练数据,那么每一次梯度调整都是奔着最理想的情况去的,但是运算能力没有这么强,于是有了批训练,梯度下降的每一步可能走的更曲折,最终可能达到最低或者局部最低
三、简单编写CNN训练代码——pytorch
PyTorch API查询— PyTorch 1.12 documentation
1. model.py
所需模块:torch.nn:定义网络各层
主要步骤:1、定义一个类继承nn.Module,用super函数继承父类
2. train.py 和 test.py
3.遇到的一些问题思考
- 使用Dataloader迭代器的时候,需要额外import torch.utils.data而不能直接使用torch.utils.data。
AttributeError: module ‘torch.utils’ has no attribute ‘data’ 解决方法_
1 | trainloader = torch.utils.data.DataLoader(dataset=trainset, batch_size=36, shuffle=True, num_workers=0) |
同理关于import的学问,matplotlib也不能用import matplotlib,而是使用
1 | from matplotlib import pyplot as plt |
- 每次训练batch时都要用zero_grad()清除优化器的梯度
Pytorch 为什么每一轮batch需要设置optimizer.zero_grad
4.模型的保存
1 | import torch |
五、训练集、验证集、测试集
训练集(Train Set): 用于训练网络的输入数据,调整网络的权重矩阵
验证集(Validation Set): 用于调整和选择模型,根据验证集产生的指标来选择最合适的训练参数,如学习率、正则化方式、Adam的参数等等。
训练和验证是在训练这个步骤里进行的,训练验证完成就已经是最优的模型
测试集(Test Set): 用于评估最终的模型
1.验证和交叉验证
收藏一个大佬的博客:验证和交叉验证(Validation & Cross Validation) - HuZihu - 博客园 (cnblogs.com)
六、Alexnet、VGG
Dropout层
训练过程中,随机失活正向传播过程中的部分神经元,防止训练过拟合
验证过程不失活
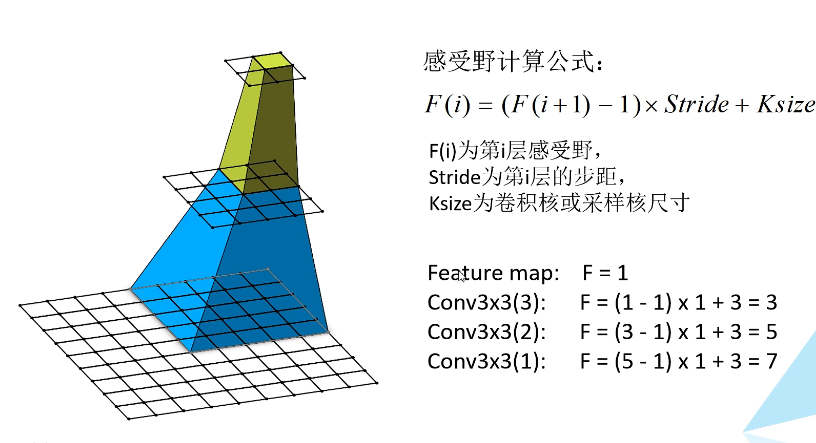
感受野Receptive field
输出特征矩阵的一个单元对应输入层上的区域大小,一种表达特征概括能力的参数。
VGG网络中用多层小卷积核来代替一个大卷积核从而减少网络参数,如3个3x3代表1个7x7卷积核,计算出来它们代表的感受野是一样的。
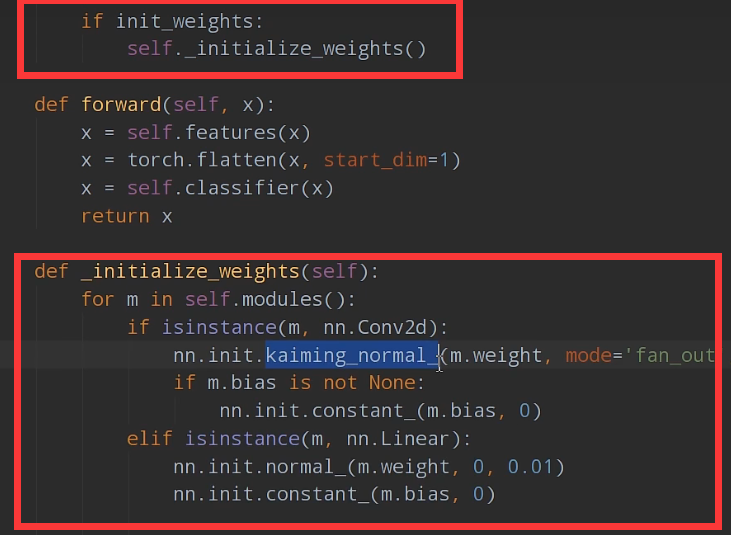
初始化权重
定义网络class的时候,可以添加是否初始化权重的参数,下列截图是初始化函数,用了凯明初始化权重法把网络里的卷积层给初始化
七、GoogLeNet
网络特点和结构
- 采用了Inception结构,融合不同尺度的特征信息
- 用1*1卷积核进行降维处理
- 添加两个辅助分类器(Auxiliary Classifier)帮助训练
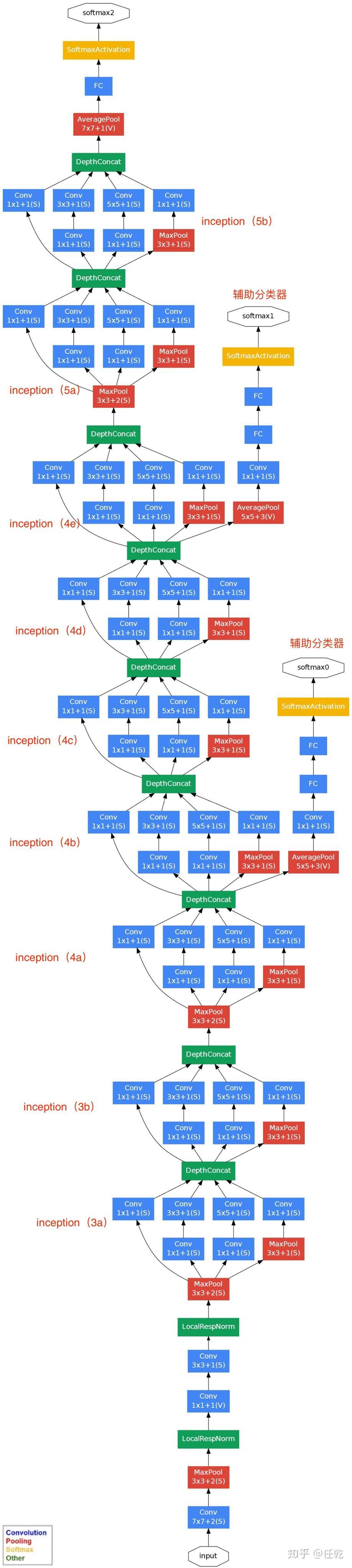
局部响应归一化(LocalResponseNorm)
辅助分类器(Auxiliary Classifier)
八、ResNet
网络结构
批归一化(Batch Normalization)
[Batch Normalization详解](https://blog.csdn.net/qq_37541097/article/details/104434557?ops_request_misc=%7B%22request%5Fid%22%3A%22165813092816781685370529%22%2C%22scm%22%3A%2220140713.130102334.pc%5Fblog.%22%7D&request_id=165813092816781685370529&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-104434557-null-null.185^v2^control&utm_term=batch normalization&spm=1018.2226.3001.4450)
迁移学习
组卷积GConv
问题
- 超参数对训练的影响:batch大小,学习率,Adam的Alpha值等等
- 看Alexnet的源码学习代码架构
- 更改loss函数对什么方面产生影响
- batchnorm(Resnet)
九、L1 L2 smooth-L1
详解L1、L2、smooth L1三类损失函数 - 腾讯云开发者社区-腾讯云 (tencent.com)
pytorch
narrow方法:提取多维tensor某一数据
AverageMeter类:记录和更新数据
view方法:重新调整tensor的形状
AdaptiveAvgPool2d()自适应平均池化:接受两个参数,分别为输出特征图的长和宽,构造模型的时候,AdaptiveAvgPool2d()的位置一般在卷积层和全连接层的交汇处,以便确定输出到Linear层的大小。
parser.add_argument:参数选择:default和action的区别,action表示该变量在命令行内被提及,parser内该变量才为true
squeeze函数:从数组的形状中删除单维度条目,即把shape中为1的维度去掉
获取tensor维度: a.shape[0],a.size(0),shape和.size()都是查看tensor维度的工具,输出torch.size(….)

